1. Распознавание языков арабского, китайского, корейского, японского, латинского и русского языков.

- Категория: Компьютерное зрение
- Заказчик: HUAWEI TECHNOLOGIES CO., LTD
- Дата: 2018-2019
SegLink с DenseNet результаты
Предварительно обученный на наборе данных SynthText






Цель
- Задача 1. Улучшение детекции арабского языка
- Задача 2. Улучшение распознавания арабского языка
- Задача 3. Улучшение распознавания китайского языка
Результаты
- Задача 1. Улучшение обнаружения арабского языка (выполнено)
- Задача 2. Улучшение распознавания арабского языка
- Задача 3. Улучшение распознавания китайского языка (выполнено)
Задание 3 технические характеристики
- Улучшить решение HQ [для распознавания китайского и английского языков] на 3% (сквозное)
- Модель должна соответствовать ограничениям NPU
Результаты распознавания китайского и английского языков < / p>
Элементы решения:
- Базовая архитектура
- Продвинутые методы обучения
- Улучшен выбор обучающих данных
| Решение | F1-score |
|---|---|
| Baseline (NLPR) | 0.908 |
| Statanly | 0.939 |
Task 1 specification
- Предоставляет единую модель обнаружения для арабского, китайского, корейского, японского, латинского и русского языков
- Для арабского языка для Kirin 980 Точность/отзыв ≥ 94/92% соответственно
- Для арабского языка для Kirin 970 Точность/отзыв ≥ 92/90% соответственно
- Не оказывает негативного влияния на обнаружение других скриптов
- Модель должна соответствовать ограничениям NPU
- Размер модели в формате Cambricon ≤ 12 Мб
Спецификация переформулирована
- Предоставляет единую модель обнаружения для арабского, китайского, корейского, японского, латинского и русского языков
- Для арабского языка для Kirin 980 Точность/отзыв сопоставима с другими языками
- Для арабского языка для Kirin 970 Точность/отзыв сопоставима с другими языками
- Не оказывает негативного влияния на обнаружение других скриптов
- Модель должна соответствовать ограничениям NPU
- Размер модели в формате Cambricon ≤ 15 Мб
Решения для детекции
Элементы решения:
- < Модель Seglink в сочетании с DenseNet
- Усовершенствованная модель EAST
- Обучен на наборе данных Batch2+арабский
- Обе модели находятся на Keras, были извлечены графики .pb
Общий результат
| Model | F (Metrics) | P (Metrics) | R (Metrics) |
|---|---|---|---|
| Seglink on DenseNet | 0.84 | 0.86 | 0.82 |
| AdvancedEAST | 0.85 | 0.97 | 0.76 |
| Baseline (HQ) | 0.82 | 0.92 | 0.76 |
Результаты по арабскому языку
| Model | F (Metrics) | P (Metrics) | R (Metrics) |
|---|---|---|---|
| Seglink on DenseNet | 0.77 | 0.71 | 0.84 |
| AdvancedEAST | 0.83 | 0.9 | 0.76 |
| Baseline (HQ) | 0.67 | 0.73 | 0.61 |
Результаты для всех языков
| Language (Script) | F (Metrics) | P (Metrics) | R (Metrics) |
|---|---|---|---|
| Arabic | 0.83 | 0.9 | 0.76 |
| English (Latin) | 0.86 | 0.96 | 0.77 |
| French (Latin) | 0.84 | 0.98 | 0.74 |
| Russian | 0.75 | 0.96 | 0.62 |
| Italian (Latin) | 0.88 | 0.98 | 0.79 |
| Chinese | 0.93 | 0.99 | 0.88 |
| Korean | 0.84 | 0.96 | 0.75 |
| Portuguese (Latin) | 0.78 | 0.98 | 0.65 |
| German (Latin) | 0.83 | 0.98 | 0.72 |
| Japanese | 0.81 | 0.97 | 0.69 |
| Spanish (Latin) | 0.85 | 0.97 | 0.75 |
Веса моделей
| Model | Weights size (MB) | Estimated size after quantization (MB) |
|---|---|---|
| Seglink on DenseNet | ~50 | ~14 |
| AdvancedEAST | ~60 | ~15 |
2. Система распознавания номерных знаков
- Категория: Компьютерное зрение
- Дата: 202-2021
- Система для анализа транспортного потока и распознавания номерных знаков в различных условиях.

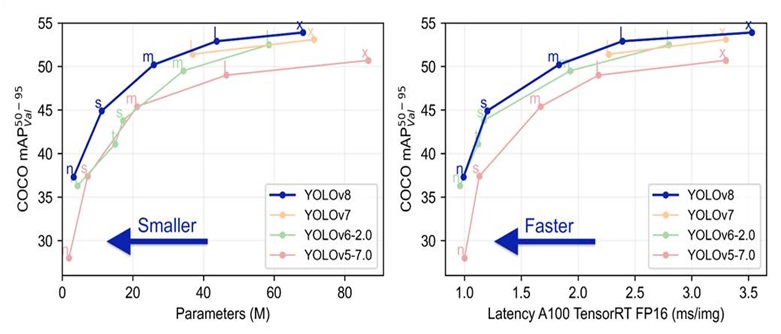
Comparison of different versions of the YOLO model by mAP (50-95) metric on the COCO dataset
Алгоритмы распознавания номерных знаков обычно состоят из двух компонентов: компонента локализации (обнаружения), который идентифицирует часть изображения, содержащую соответствующую информацию, и компонента генерации набора символов, который извлекает символы из выбранной области.
Чтобы выбрать модель обнаружения, был проведен тщательный анализ литературы, выявивший наилучшие модели как с точки зрения скорости, так и точности обнаружения. В то время было определено, что модель YOLOv5 является оптимальным выбором, обеспечивая точность, сравнимую с моделями SOTA, при впечатляющей производительности.
Аналогичным образом был проведен анализ литературы для изучения моделей SOTA для распознавания текста по изображениям (OCR). Хотя существуют различные решения, основанные на архитектуре Transformer, они часто демонстрируют более низкую производительность. В результате модель CRNN была определена как наиболее подходящая для решения поставленной задачи.
Существующий набор данных был преобразован для переобучения модели YOLOv5, что потребовало десяти периодов обучения для наблюдения желаемых улучшений.
Впоследствии переобученная модель YOLOv5 была использована для построения набора данных, состоящего исключительно из изображений номерных знаков. Аннотации к числам были получены из исходного набора данных. Затем модель CRNN была повторно обучена на этом модифицированном наборе данных, достигнув точности распознавания 96% на тестовом образце.
Модели YOLOv5 (обнаружение) и CRNN (распознавание) были интегрированы в библиотечный компонент для распознавания номерных знаков из видеопотока, легко интегрируясь с существующей архитектурой библиотеки. Во время разработки этого модуля ultralytics выпустила несколько моделей YOLO. Версия YOLOv8n, обладающая точностью обнаружения, сравнимой с YOLOv5s, но меньшим количеством параметров и более высокой скоростью, была включена в алгоритм и дополнительно доработана для распознавания номерных знаков.
Чтобы обеспечить максимальную стабильность алгоритмов в неблагоприятных погодных условиях, были реализованы методы увеличения изображения и методы проективной геометрии. Дополнение - это процесс обогащения набора данных путем создания их “искаженных” версий. Было реализовано несколько типов искажений:
- Shifts
- Turns
- Glare
- Defocus
- Compression and tension
- Color (for simulating night filters)
Расширение доступных наборов данных сделало модели более устойчивыми к различным погодным условиям.
Чтобы оценить эффективность алгоритма в сложных погодных условиях, с помощью сервиса Roboflow были собраны и помечены дополнительные 357 тестовых изображений автомобилей (снятых при плохом освещении, снеге, дожде). Примеры таких изображений:

3. Распознавание номера вагона поезда
- Категория: Компьютерное зрение
- Заказчик: Транспортная компания
- Project date: 2022
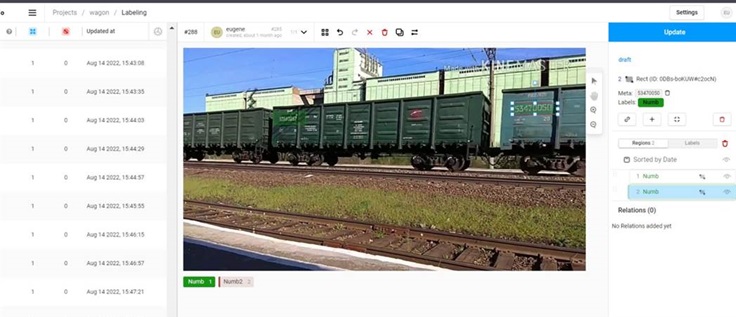
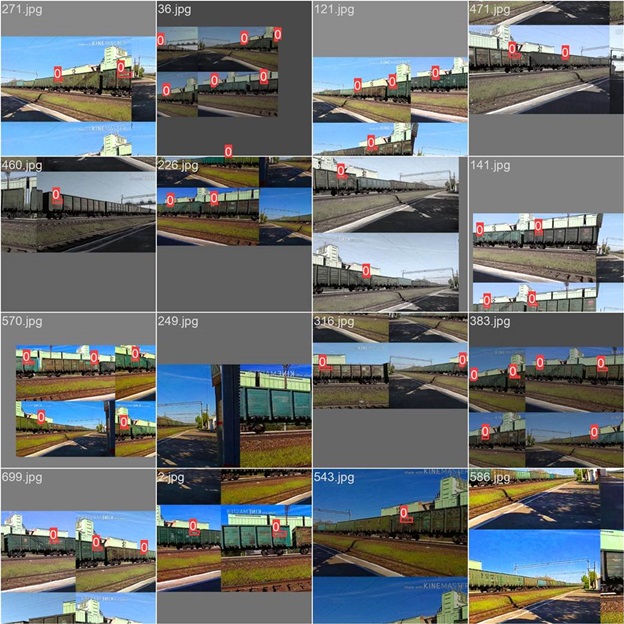
Создание обучающих примеров на основе естественных изображений предполагает сбор реальных данных с помощью различных средств:
- Коллекция изображений (фотографирование интересующих объектов, захват видеопотока с камеры, выделение части изображения на веб-странице).
- Фильтрация - проверка изображений на соответствие ряду требований: адекватное освещение объекта, наличие целевого объекта и т.д.
- Подготовка инструментов аннотации (разработка пользовательских инструментов аннотации или оптимизация существующих).
- Разметка (выделение интересующих прямоугольников или областей на изображениях).
- Присвоение метки каждому изображению (буква или название объекта на изображении).
В рамках начальной фазы проекта был организован сбор данных, включая фотографирование и запись проходящих поездов в различных условиях. Затем собранные данные были помечены с помощью инструмента Label Studio, отметив координаты ограничивающего прямоугольника для каждого номера автомобиля.
Компоненты обнаружения (YOLOv8) и распознавания (CRNN) впоследствии были переобучены на собранном наборе данных для распознавания автомобильных номеров. Общая точность распознавания на тестовом образце составила 89%, что указывает на то, что модель правильно распознает все символы номера в 89% случаев. Этот результат демонстрирует способность модели хорошо обобщаться на связанные проблемы, которые могут быть дополнительно улучшены с помощью дополнительных помеченных примеров.
4. Система распознавания QR-кода и штрих-кодов
- Категория: Компьютерное зрение
- Заказчик: Транспортная компания
- Project date: 2022



Results of analysis
Были рассмотрены существующие решения для распознавания QR-кода и штрих-кодов. Запуск библиотеки OpenCV с использованием алгоритма zbar показал, что QR-коды, как правило, обнаруживаются более эффективно, чем штрих-коды того же размера. Результаты анализа качества считывания представлены на рисунке и более подробно обсуждаются ниже.
Эмпирические наблюдения показали, что сложные QR-коды начинают обнаруживаться и считываться правильно, когда они занимают примерно 0,8% кадра, в то время как более простые коды занимают около 0,64% кадра. Коды ниже примерно 0,74% для сложных QR-кодов и 0,57% для простых больше не были надежно обнаружены.
С другой стороны, штрих-коды сталкиваются с трудностями из-за близко расположенных полос, что часто приводит к размытию рамок. В отличие от QR-кодов, штрих-коды могут быть частично считаны, даже если они в некоторой степени обрезаны по горизонтали, хотя данные могут быть неполными. Например, некоторые кадры могут считывать область размером всего 0,04% от кадра, в то время как обнаружение ниже 0,74% может работать некорректно. Если во время обнаружения присутствует более 0,91% площади и она не обрезана, коды распознаются четко и полно.
В ходе экспериментов было определено расстояние, с которого все коды были легко обнаружены (QR-коды размером 1,26 см для простых и 1,55 см для сложных). При повороте на угол 43 градуса коды больше не считывались. Однако, когда угол поворота был уменьшен до 40 градусов или меньше, все коды считывались правильно. Точку перехода от нечитаемости сложного кода к удобочитаемости простого кода точно определить не удалось, поскольку и то, и другое произошло примерно в одно и то же время.
Для штрих-кодов было определено расстояние, с которого все коды были легко обнаружены (размеры штрих-кодов приблизительно занимали 0,96% кадра). При повороте на угол 43 градуса коды больше не считывались. При угле поворота в 40 градусов не все коды были считаны успешно, а те, которые были считаны, содержали ошибки обнаружения, что приводило к неправильным показаниям. Начиная с угла поворота в 33 градуса, все стало читаемым, но время от времени стали возникать ошибки обнаружения. При повороте на 30 градусов или меньше все считывалось правильно.
Основываясь на удовлетворительных результатах, достигнутых с использованием библиотеки OpenCV с добавлением библиотеки zbar, было принято решение адаптировать существующее решение.
5. Система распознавания текста в произвольной форме
- Категория: Компьютерное зрение
- Заказчик: Транспортная компания
- Project date: 2022
- Description: Recognition of text of arbitrary form, various fonts, markings, inscriptions in conditions of various noise levels and for various alphabets



Чтобы сравнить производительность существующих библиотек распознавания символов, а именно Paddle OCR, Tesseract, Doctr и EasyOCR, был собран набор данных из 1210 фотографий созданных объектов (металл, пластик, стекло, кирпич, бумага, дерево). Средние расстояния Левенштейна между распознанными надписями и исходным текстом были рассчитаны для различных категорий материалов, как представлено в таблице:
| Material/Model | PaddleOCR | Tesseract | Doctr | Doctr |
|---|---|---|---|---|
| Metal | 0.057160 | 0.461613 | 0.268681 | 0.181886 |
| Brick | 0.353260 | 0.041227 | 0.335991 | 0.103651 |
| Glass | 0.307380 | 0.254498 | 0.270838 | 0.212571 |
| Plastic | 0.947816 | 0.210128 | 0.147302 | 0.017100 |
| Paper | 0.377727 | 0.223795 | 0.270136 | 0.135312 |
| Wood | 0.055672 | 0.189703 | 0.188016 | 0.014465 |
| Miscellaneous | 0.124016 | 0.045473 | 0.021668 | 0.031424 |
Результаты показали, что существенный фактор ошибок связан с неправильным определением положения текста на изображении. Чтобы решить эту проблему, для обнаружения текста был использован внешний детектор, небольшая модель YOLOv8. Однако первоначальные взвешивания дали неудовлетворительные результаты. Чтобы еще больше повысить его производительность, для дополнительного обучения был создан синтетический набор данных, содержащий 10 000 фотографий промышленных помещений с текстом, выполненным различными латинскими и кириллическими шрифтами.
Основываясь на результатах тестирования с использованием реальных данных, алгоритм достиг точности 0,3, которая зависит от условий фотографирования чисел на объектах. Фотографии должны быть четкими и снятыми при хорошем освещении. Угол наклона текста не должен превышать 20 градусов, а для успешного распознавания текст должен занимать не менее 1,5% кадра. Текст, написанный вертикально, не может быть надежно распознан, в то время как цифры, написанные на пластике, стекле, бумаге и картоне, дают наилучшие результаты распознавания.